

{kind=link}
What is Information Gain?
Information Gain is a concept in data science and machine learning, typically used to measure how much “new” or unique information a specific data point or document provides relative to what is already known.
In simpler terms, it’s a metric that indicates the additional value a particular piece of content or document contributes when it is selected. In the context of search, Information Gain ensures that content shown to users brings unique insights or details not previously encountered, effectively filtering redundant results.
Information Gain as a concept gained popularity after a patent filed by Google in 2020.
About the Patent on Information Gain
The patent, “Contextual Estimation of Link Information Gain,” was filed by Google, focusing on optimizing the search process by introducing the concept of “information gain.”
Published in November 2020, the patent describes a method to enhance search relevance by measuring the potential value of each document based on its unique, additional information relative to previously viewed content.
This approach ensures that users are not repetitively presented with similar content and instead receive documents that provide new insights or knowledge. By implementing Information Gain in its search algorithms, Google aims to improve user experience, refining the relevance of results in each interaction.
What does Information Gain do?
Information gain identifies how much additional value or unique information a specific piece of content provides compared to what is already known or previously viewed.
This approach helps search engines like Google to model user interactions based on previously viewed content, allowing them to rank similar documents or pages in search results with greater relevance.
By leveraging machine learning models and vast amounts of search behavior data, Google can predict and rank new content that provides unique information or insights, enhancing user satisfaction and engagement.
How does Information Gain Work?
Information Gain functions by assigning scores to content based on how much new information it adds compared to previously viewed documents.
Information Gain scoring is heavily reliant on machine learning models, particularly using semantic representations of documents. This includes techniques like word embeddings or vectors (e.g., Word2Vec), which map words and documents into vector spaces, allowing the algorithm to assess the similarity and uniqueness of content more effectively.
Each document is assigned an Information Gain score ranging from 0 to 1, indicating its uniqueness compared to already-viewed content.
Here’s a breakdown of how this process works according to the patent:
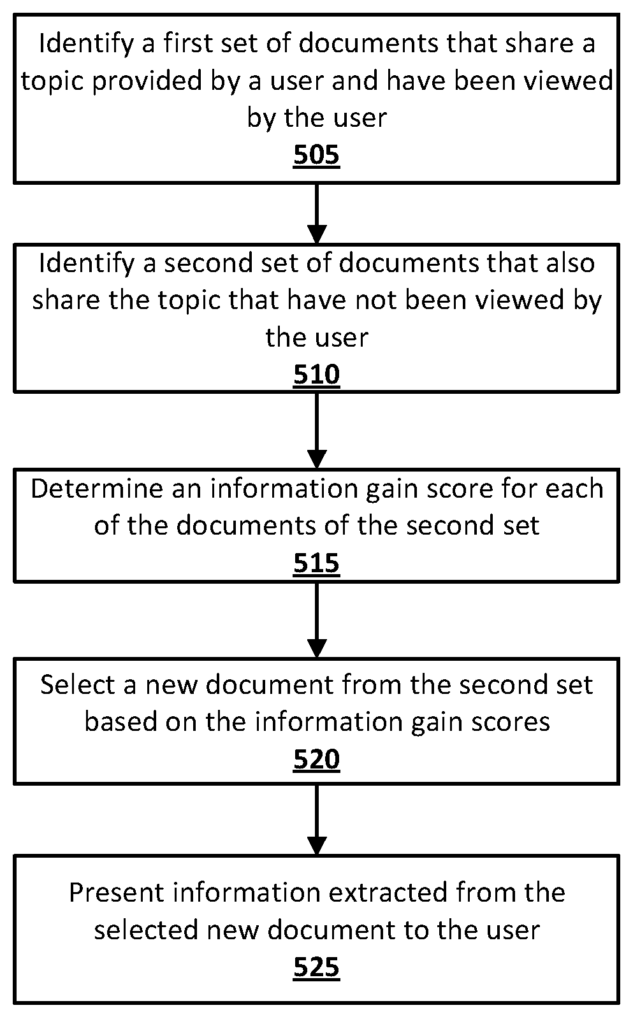
1. Identifying Document Sets
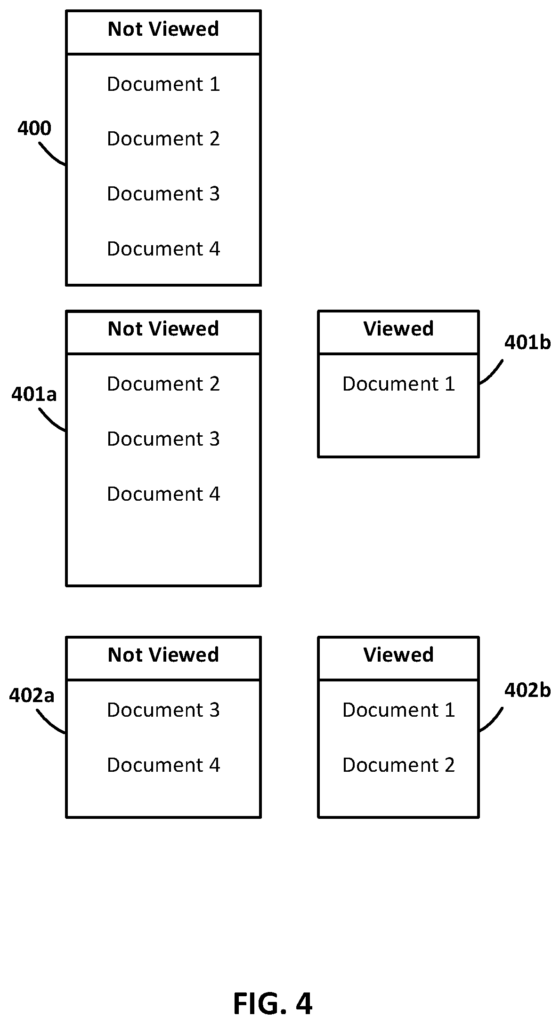
The algorithm first categorizes documents into two sets: those already seen by the user and those that have not been viewed. This is fundamental to understanding what the user has already consumed.
First Set (Viewed Documents): Identify the documents the user has already seen. These serve as the baseline for what information the user already knows.
Second Set (Unviewed Documents): Identify new documents that share a common topic but have not been viewed by the user.
2. Scoring with Machine Learning Models
Machine learning models analyze the contents of each document, generating a unique score called the “Information Gain Score.” This score is derived by evaluating how much novel information a document presents compared to previously viewed content.
Semantic Vectorization: Each document is transformed into a numeric vector that captures its meaning. This is often done using models like Word2Vec, BERT, or custom embeddings.
Generate Feature Vectors: Each document is represented as a semantic vector, encoding unique features of the document. Vectors are generated for both the previously viewed documents and the new, unviewed document(s).
Mathematical Formula for Information Gain Score Calculation (Example)
Though specific formulas may vary by implementation, one common formula for calculating Information Gain in text processing can be adapted as follows:
Information Gain (IG) = 1− (Overlap(Dnew,Dviewed) / Total Information(Dnew))
- Overlap measures the similarity between the new document and already viewed documents.
- Total Information captures the entirety of content in the new document.
- Information Gain is high when Overlap is low, meaning the new document brings more unique information.
3. Ranking and Selection
Documents with the highest Information Gain Scores are prioritized. This ranking system ensures that users receive content offering the most significant new insights, rather than reiterations of information they’ve already accessed.
Additionally, the model uses semantic feature vectors or embeddings (transforming text into numeric data points that capture meaning) to identify similarities and differences between documents. By reranking content each time the user interacts with a document, the search engine continuously adapts the results based on newly gathered information, optimizing for unique content at each step.
Reranking & Real-time Scoring
Reranking: Based on the calculated Information Gain scores, the system ranks the unviewed documents. Higher-scoring documents are prioritized, ensuring that users receive content with the greatest unique value first.
Potential for Real-Time Scoring: As users interact with additional documents, the Information Gain scores for the remaining documents are recalculated. For instance, if the user has now viewed Document 2, the score for Document 3 may decrease if it overlaps with the information presented in both Documents 1 and 2.
Real-time scoring doesn’t necessarily update every interaction instantly but is based on defined triggers or contextual signals.
Impact of Information Gain on Search
Information Gain has transformed the search landscape, enabling search engines to deliver content with higher relevance by preventing redundancy. Here are key impacts on search engines:
- Enhanced User Experience: By prioritizing diverse content, users are less likely to encounter repetitive information, making their search journeys smoother and more insightful.
- Improved Content Discovery: Information Gain boosts the visibility of niche content, as it selects documents with less overlap with previously viewed information. Users discover new perspectives or lesser-known facts more easily.
- Efficiency in Interaction: For users with complex or evolving queries, Information Gain can shorten the search process by offering fresh insights each time, creating a progressive discovery model that encourages further exploration.
How Information Gain Impacts SEO?
From an SEO perspective, Information Gain presents unique challenges and opportunities:
1. Content Originality Becomes Essential
With Information Gain, search engines now value the uniqueness of information within a webpage. Content that simply repeats what exists across the web may rank lower, while original content is rewarded.
Information Gain is more about unique value-add rather than strict originality. Content may rank well not only if it’s unique but also if it adds a valuable perspective on similar information, enriching the overall user experience.
2. Increasing Content Depth and Relevance
SEO strategies should aim to produce comprehensive content that covers unique aspects of a topic, offering value that competitors may not. This approach aligns well with the Information Gain model, as Google prefers diverse perspectives that reduce redundancy in search results.
3. Adapting to User Intent Variability
Optimizing for Information Gain encourages SEOs to consider different angles, subtopics, or uncommon questions within a topic. This not only meets diverse user intents but also satisfies Information Gain’s preference for varied information within a theme.
4. Potential for Updated Content – Content Freshness
Regularly updating content with new insights, statistics, or case studies can increase its relevance, especially in domains where information changes frequently. Content that demonstrates a consistent Information Gain for returning queries will likely perform better in search rankings.
This means “Content freshness” is likely to be a factor that can be tweaked to improve search visibility. However, content freshness without any information gain may not be that impactful.
Subscribe to Our Newsletter!
Very detailed but easy to understand explanation. Thank you!
“Information Gain is more about unique value-add rather than strict originality.” – I liked the way you have put it across. There are a lot of misinformation about this patent going on. You have covered it true to the source.