
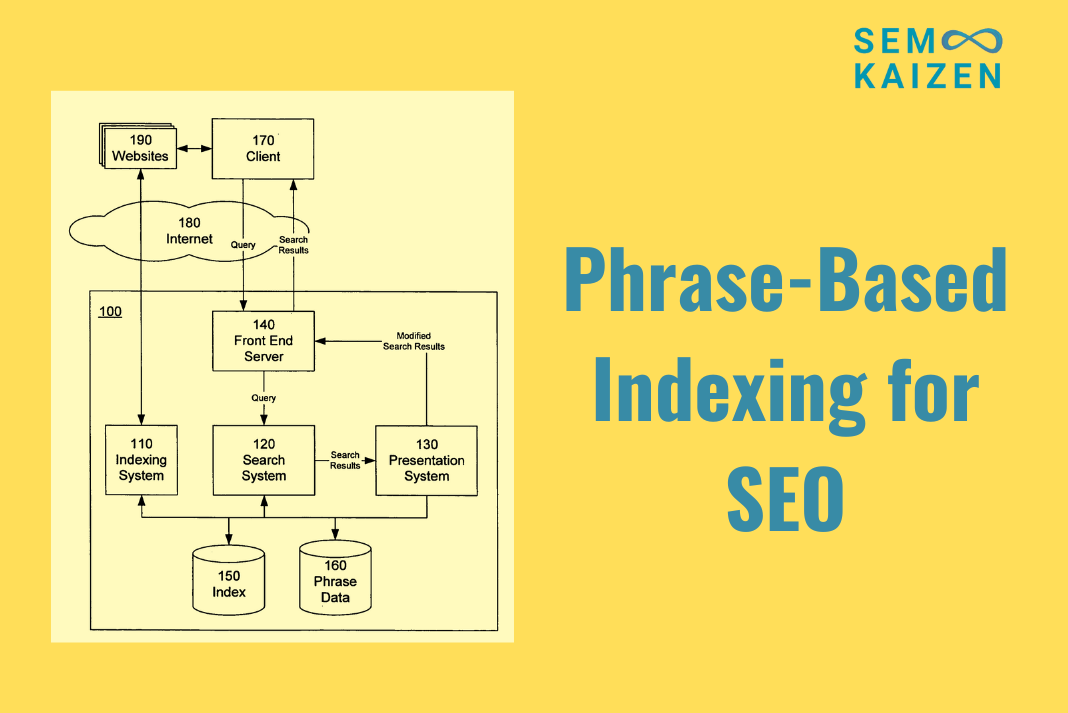
{kind=link}
Phrase-based indexing is an advanced information retrieval technique used by search engines like Google to improve the relevance and accuracy of search results.
Unlike traditional keyword-based indexing, where individual words are indexed and matched against search queries, phrase-based indexing focuses on indexing multi-word phrases, considering them as single units of meaning. This approach helps capture the context and relationship between words, leading to a better understanding of the user’s intent and more precise results.
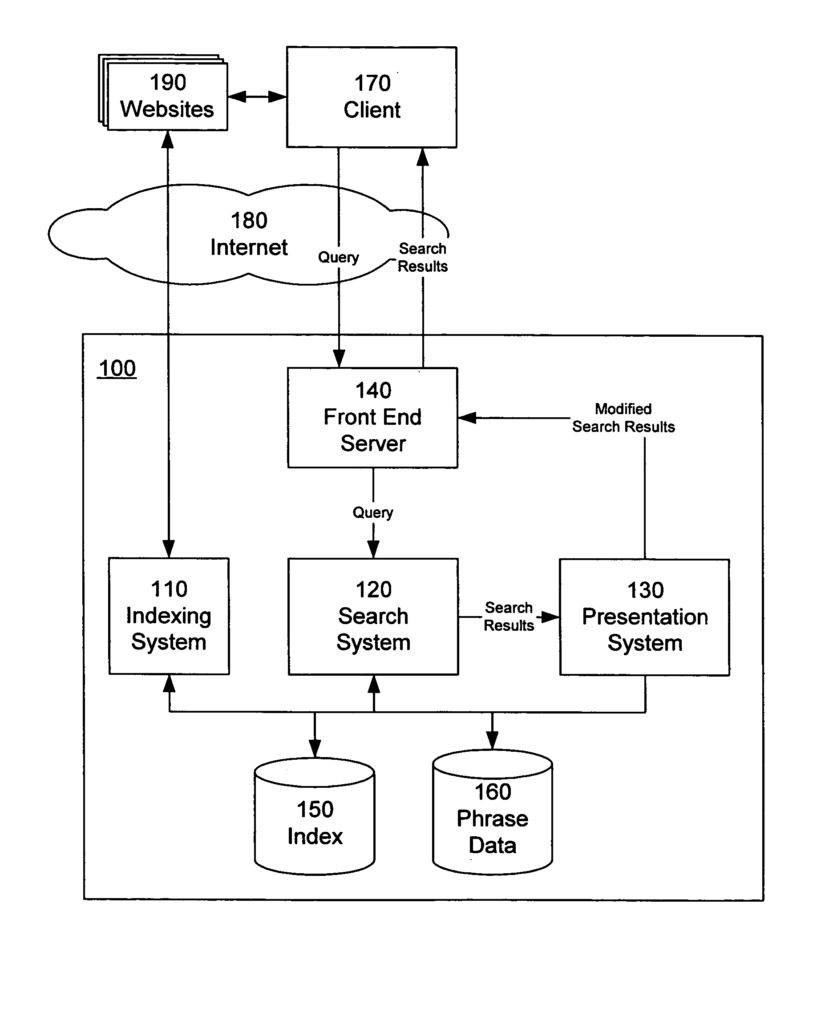
Who is behind the Phrase-Based Indexing System?
Ex-Googler Anna Patterson is the listed inventor on many patent applications that describe phrase-based indexing systems.

How Phrase-Based Indexing Works?
Phrase-based indexing enhances traditional keyword-based search by focusing on phrases rather than individual words. It captures the relationship between words in a phrase, providing more context and precision in search results.
Phrase-based indexing involves several steps:
1. Phrase Extraction
Search engines analyze documents and extract common phrases or word sequences from the content. These phrases can be bi-grams (two-word phrases), tri-grams (three-word phrases), or longer, depending on the complexity and structure of the document.
The first step in phrase-based indexing is identifying meaningful phrases from a document or webpage. These can be two-word phrases (bi-grams), three-word phrases (tri-grams), or longer phrases that convey a specific concept.
Example:
Consider the sentence: “Artificial intelligence and machine learning are shaping the future of technology.”
Phrase Extraction would identify meaningful phrases like:
- “Artificial intelligence”
- “Machine learning”
- “Future of technology”
These phrases represent complete ideas, whereas individual words like “artificial” or “learning” would be ambiguous on their own.
Good vs. Bad Phrases
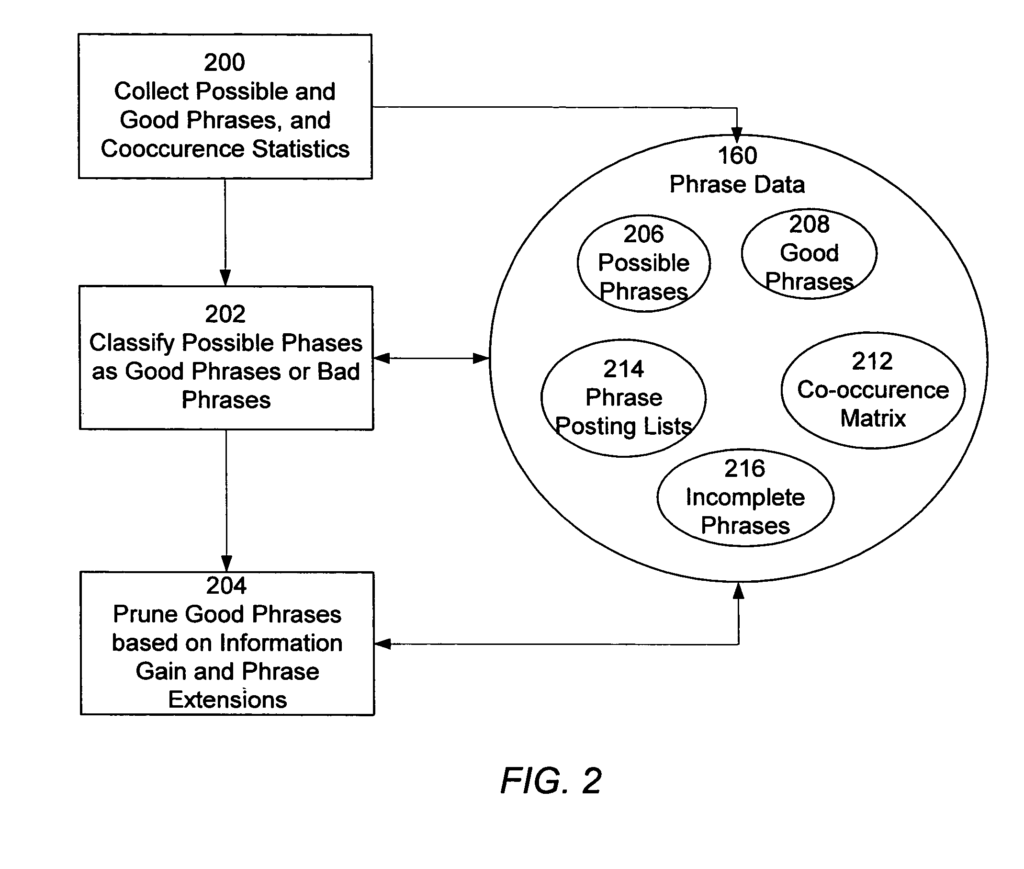
The system distinguishes between phrases with meaningful patterns (good phrases) and those without predictive power (bad phrases). Good phrases predict the presence of other phrases.
Good Phrases:
Good phrases are those that meet certain criteria for being useful in indexing and searching documents. They tend to:
- Appear frequently in multiple documents, indicating they are significant and commonly used.
- Predict other phrases in the document, meaning the presence of one good phrase makes it likely that another related phrase will also appear.
- Carry meaning or represent a concept (e.g., “Artificial Intelligence” or “President of the United States”). These phrases are contextually rich and provide value for understanding document content.
Characteristics of Good Phrases:
- Frequency Threshold: Good phrases are those that appear in a significant number of documents. For example, a phrase that appears in more than 10 documents and occurs more than 20 times may qualify as a good phrase.
- Predictive Power: A good phrase predicts the appearance of other meaningful phrases in a document. For instance, “Artificial Intelligence” might predict the phrase “Machine Learning.”
- Distinguished Usage: Some good phrases are identified because they are highlighted in a document, such as being bolded, italicized, or appearing in headings or anchor text (e.g., a hyperlink).
Example:
- “Artificial Intelligence” is a good phrase because it occurs frequently in documents related to technology and can predict related phrases like “Machine Learning,” “Deep Learning,” and “Neural Networks.”
Bad Phrases:
Bad phrases, on the other hand, do not contribute meaningfully to the indexing and search process. They:
- Appear infrequently or in very few documents, making them statistically insignificant.
- Lack of predictive power, meaning they do not consistently co-occur with other relevant phrases in a way that would help the system retrieve related documents.
- These are often random or idiomatic expressions (e.g., “out of the blue”) that don’t have specific meaning in the context of document indexing.
Characteristics of Bad Phrases:
- Low Frequency: Phrases that appear in very few documents (e.g., less than 2 documents) and are not used frequently within those documents.
- No Predictive Power: Phrases that do not predict the presence of any other significant phrases. For example, idioms or colloquial expressions that appear randomly without context (e.g., “fell down the stairs”) would be considered bad phrases.
- Irrelevant Context: These phrases are often not associated with meaningful topics or concepts that contribute to the understanding of the document’s content.
Example:
“Out of the blue” is a bad phrase because it is an idiomatic expression that doesn’t predict other meaningful phrases or help categorize document content.
Information Gain
Information gain refers to extra information in a document that goes beyond what a user has already seen in other documents. An information gain score is sometimes calculated by running document data through a machine learning model, which measures how much new information the document provides.
Information gain helps re-rank search results based on user behavior on the SERP. It functions similarly to the concept of long clicks and short clicks—where user pogo-sticking and scanning through different search results contributes to ranking or demoting results.
2. Contextual Understanding
The search engine understands the relationship between the phrases. For example, phrases like “machine learning” and “artificial intelligence” are context-related, even if they don’t share the same words.
Phrase-based indexing goes beyond exact word matching to understand the context of phrases. It groups related phrases together based on their usage in various documents and analyzes their co-occurrence.
Example:
In different documents, phrases like “artificial intelligence” and “machine learning” might frequently appear together. The search engine recognizes that these two phrases are related, even though they don’t share common words.
When a user searches for “machine learning techniques,” the search engine can also surface documents that talk about “artificial intelligence techniques” because it understands the contextual relationship between the two topics.
3. Indexing Phrases
Once extracted and analyzed, the search engine indexes these phrases and stores them in its database. Instead of simply indexing individual keywords, it now understands and stores multi-word phrases that carry more contextual meaning.
Once phrases are extracted and analyzed, they are indexed in the search engine’s database. This means each document is indexed not just based on individual words but also on meaningful multi-word phrases.
Example:
A document that contains phrases like “best wireless headphones,” “noise cancellation,” and “Bluetooth connectivity” will have these indexed as phrases, allowing the search engine to retrieve this document more accurately when a user searches for those terms.
Let’s say a user searches for:
“best wireless headphones for gym”
The search engine doesn’t just look for each word separately but searches for the exact phrase “best wireless headphones.” If a document has this phrase, it’s more likely to rank higher in the search results because the phrase aligns with the query’s intent.
4. Phrase Matching in User Queries
When a user enters a search query, the search engine checks for phrases rather than just individual words. By understanding the user’s intent, it prioritizes documents that contain relevant phrases, ensuring more accurate search results.
Example 1: Precision Matching
Query: “How to improve user experience in web design?”
In this case, the search engine will match phrases like:
“User experience”
“Web design”
“Improve user experience”
It won’t just search for “user,” “experience,” and “web” separately. This avoids irrelevant results like articles that discuss “user profiles” or “experience in web programming” but not user experience in web design.
Example 2: Handling Variations
Query: “Top programming languages for AI development”
Phrase-based indexing can also handle variations of phrases. For instance, it knows that “programming languages for AI” and “AI programming languages” are contextually similar, so it can match both phrases with the query.
Even if an exact phrase match isn’t present, the search engine understands the related terms, providing better results.
5. Ranking Based on Phrases
When a user enters a search query, the search engine matches the query not just with individual words, but with indexed phrases. This allows for more accurate and context-driven results, ranking pages that include relevant phrases higher in the results.
After phrase matching, the search engine ranks documents based on the relevance of the phrases. If a document has multiple high-relevance phrases matching the query, it is more likely to appear at the top of the search results.
Example:
Let’s compare two documents for the query “benefits of a plant-based diet.”
- Document A has phrases like:
- “Plant-based diet”
- “Health benefits”
- “Nutritional value of plant-based foods”
- Document B mentions these phrases less frequently or has less relevant content.
Document A will be ranked higher because its phrases align more closely with the user’s query.
Different Kinds of Rankings in Phrase-Based Indexing
- Phrase Relevance Ranking: Focuses on exact phrase matches.
- Information Gain-Based Ranking: Prioritizes documents where phrases predict each other.
- Cluster-Based Ranking: Groups documents by related phrase clusters.
- Related Phrase Ranking: Ranks documents by synonyms or semantically related phrases.
- Document Popularity Ranking: Accounts for document popularity and user interaction.
- Personalized Ranking: Customizes rankings based on user behavior and preferences.
- Proximity-Based Ranking: Ranks higher when relevant phrases appear close together.
- Recency-Based Ranking: Prioritizes more recent documents in certain contexts.
What is Clustering in Phrase-Based Indexing
Clustering is the process of grouping related phrases or documents based on their semantic similarity or co-occurrence patterns. The goal of clustering is to organize phrases or documents into meaningful groups (clusters) that represent a common theme, topic, or concept. This helps improve the efficiency and relevance of search results in information retrieval systems.
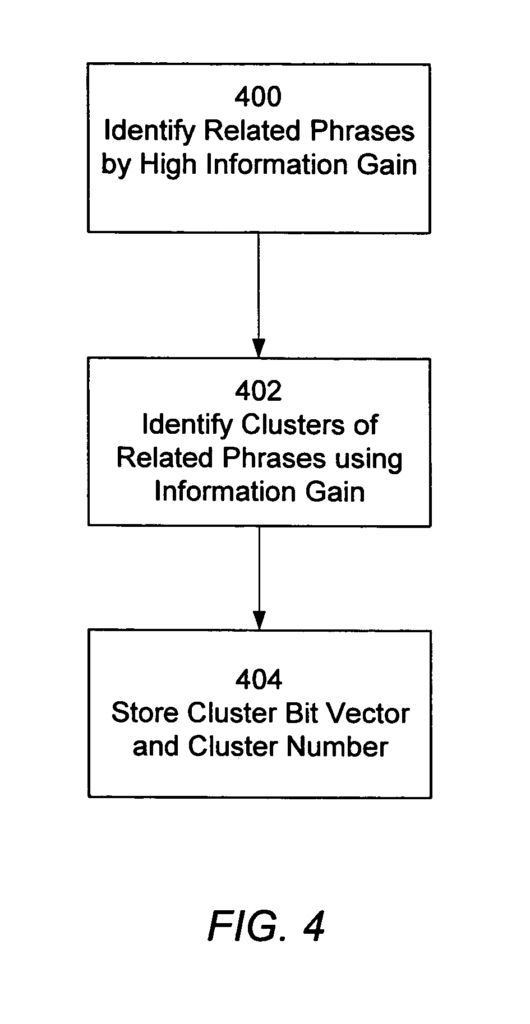
Key Aspects of Clustering in Phrase-Based Indexing
- Related Phrases Clustering: Phrases that frequently appear together or are contextually linked in a document are grouped into clusters. The system calculates how closely related the phrases are based on their co-occurrence and information gain (a measure of how much the presence of one phrase predicts another).
- Information Gain: This metric is used to evaluate the strength of the relationship between two phrases. If two phrases co-occur much more often than would be expected by chance, they are considered strongly related and may be grouped into the same cluster.
- Example: For the phrase “Bill Clinton,” related phrases like “President” and “White House” might form a cluster because they frequently appear together in documents about U.S. politics.
- Cluster Creation: Clusters are formed by identifying phrases that are closely related to each other based on their co-occurrence patterns. If multiple phrases share a high degree of information gain with each other, they are grouped into a cluster.
- Example: A cluster of phrases related to “Artificial Intelligence” might include “Machine Learning,” “Neural Networks,” and “Deep Learning” because these phrases often appear together in technical documents.
- Cluster Representation: Each cluster can be represented by a bit vector or a cluster ID that encodes the relationship between phrases. The bit vector indicates which phrases belong to the same cluster, while the cluster ID uniquely identifies each cluster.
- Example: If “Machine Learning” and “Deep Learning” are in the same cluster, their cluster ID might be the same, or the bit vector would show a common pattern indicating their relationship.
- Use in Search Results: Clustering improves search results by organizing them into relevant groups. When a user performs a search, the system can present results clustered by topic, making it easier to find related documents.
- Example: If a user searches for “AI technology,” the system could return clusters of documents organized by topics like “AI in Healthcare,” “AI in Finance,” or “AI in Robotics.”
- Document Clustering: In addition to phrases, documents themselves can also be clustered based on the phrases they contain. This allows for the grouping of similar documents, enhancing the search experience by providing users with a set of related documents on the same topic.
- Example: Documents discussing “COVID-19 vaccines” might be clustered together because they share common phrases like “Pfizer,” “Moderna,” and “vaccination.”
Benefits of Clustering in Phrase-Based Indexing
- Improved Search Accuracy: Clustering helps the system return more relevant results by grouping related phrases and documents, reducing the chances of irrelevant content showing up.
- Topic Organization: Clusters allow search results to be organized by topic, making it easier for users to explore related content.
- Efficient Query Processing: By clustering phrases, the system can speed up search processes by focusing on groups of related phrases instead of processing each phrase individually.
Example of Clustering in Action
Let’s say the system is indexing documents about computer science. It might create clusters of related phrases like:
- Cluster 1: “Artificial Intelligence,” “Machine Learning,” “Deep Learning”
- Cluster 2: “Programming Languages,” “Python,” “Java,” “C++”
- Cluster 3: “Cloud Computing,” “AWS,” “Microsoft Azure”
When a user searches for “Machine Learning,” the system will prioritize documents that include phrases from Cluster 1 and rank those documents higher because they are more contextually relevant to the query.
Handling Spam in Phrase-Based Indexing
Phrase-based indexing system uses duplicate detection to control spam while indexing & ranking documents on the search.
Duplicate detection in phrase-based indexing refers to the process of identifying and eliminating duplicate or nearly identical documents from the search results or index. This is crucial in large-scale information retrieval systems, such as search engines, to ensure that users are not presented with multiple instances of the same or highly similar content. Duplicate detection enhances user experience by improving the diversity and relevance of search results, reducing redundancy.
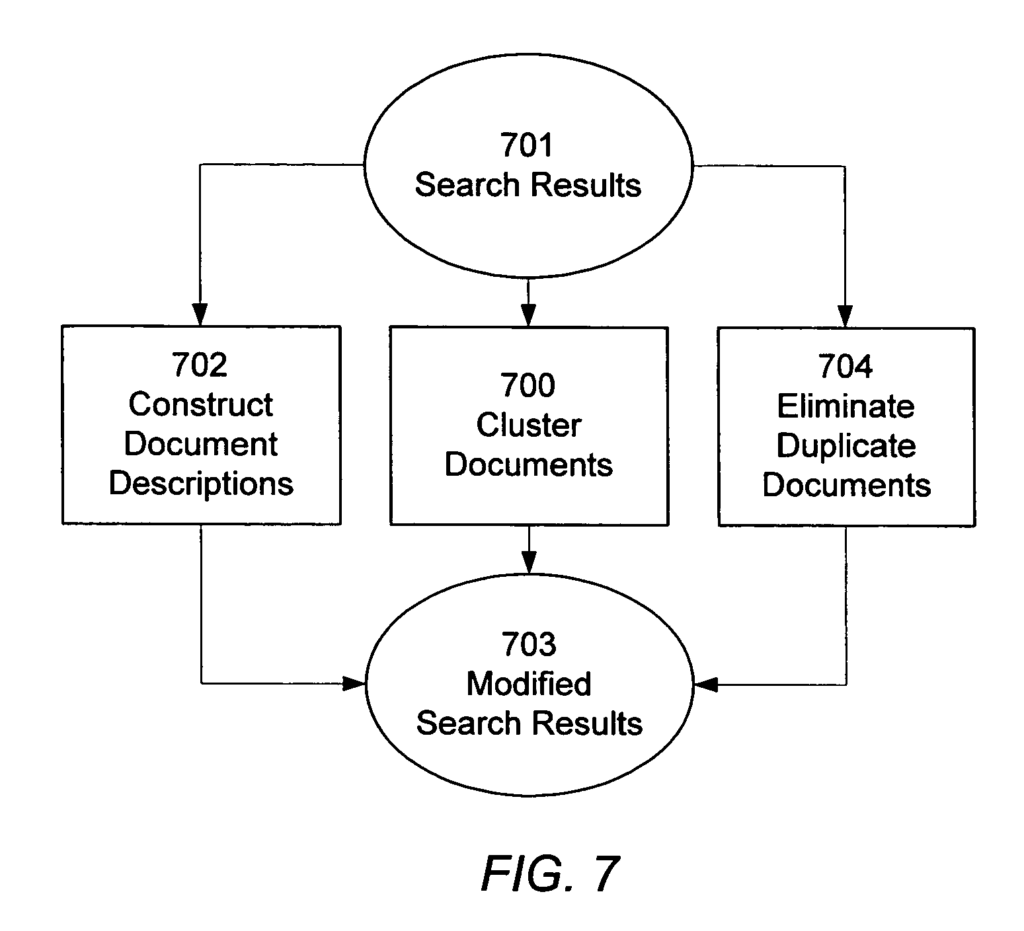
Key Concepts of Duplicate Detection
- Phrase-Based Document Representation:
- In phrase-based indexing, each document is represented by the phrases it contains. These phrases form a document signature or description, which the system uses to detect duplicates.
- When a document is crawled, the system extracts important phrases and builds a phrase-based summary or hash of the document’s content. This summary becomes a key part of duplicate detection.
- Document Descriptions:
- A document description is a concise representation of the most important phrases in the document. It may be generated by selecting the sentences with the highest number of query-related phrases or related phrase clusters.
- For example, if a document contains the phrase “Artificial Intelligence” frequently, along with related phrases like “Machine Learning” and “Neural Networks,” the document description will summarize these key points.
- Similarity Measurement:
- To detect duplicates, the system compares the document descriptions (or signatures) of two or more documents. If their phrase-based summaries are similar beyond a certain threshold, the system considers them duplicates.
- Hashing: A common technique is to create a hash of the document description (a unique numerical value representing the document’s key phrases). If two documents have the same or similar hash values, they are likely duplicates.
- Threshold for Similarity: The system sets a similarity threshold (e.g., 90%) to determine when two documents are considered duplicates. If the similarity between the two document descriptions exceeds this threshold, one of the documents is flagged as a duplicate.
- Handling Partial Duplicates:
- In some cases, documents may not be exact duplicates but contain large portions of identical or highly similar content. These are called partial duplicates.
- Phrase-based indexing can detect partial duplicates by identifying common clusters of phrases or paragraphs that are repeated across documents. This allows the system to remove redundant sections while retaining unique content.
- Duplicate Elimination in Indexing:
- During the indexing phase, duplicate detection ensures that only one instance of each document (or the most relevant version) is included in the index. When a new document is crawled, its document description is compared against already-indexed documents.
- If a duplicate is detected, the new document is either discarded or merged with the existing indexed document. This helps in reducing the overall index size and improving search speed.
- Duplicate Elimination in Search Results:
- When a user submits a query, the system retrieves relevant documents. Before presenting the results, duplicate detection algorithms eliminate redundant documents, ensuring the user sees a diverse set of results.
- Near-Duplicate Filtering: This process filters out documents that contain similar content but may differ slightly (e.g., different URLs showing the same article).
Example of Duplicate Detection
Let’s say two documents about “machine learning algorithms” are indexed:
- Document A: Contains phrases like “Machine Learning,” “Supervised Learning,” “Neural Networks.”
- Document B: Contains almost the same content as Document A but with slight variations in wording.
In this case, the system would:
- Generate document descriptions based on the key phrases from both documents.
- Compare the descriptions and detect that the content overlap exceeds the predefined threshold.
- Flag Document B as a duplicate and either remove it from the search results or merge it with Document A.
Techniques Used in Duplicate Detection
- Shingling (or N-Gram Matching)
- Shingling breaks down a document into smaller chunks (n-grams), such as sequences of words or phrases, and compares these across documents.
- If two documents share a large number of shingles (overlapping chunks), they are flagged as duplicates.
- Hashing Algorithms
- Simhash or Minhash algorithms are commonly used for detecting near-duplicates. These methods create a condensed hash value of a document’s content. If two documents have similar hash values, they are likely duplicates.
- TF-IDF (Term Frequency-Inverse Document Frequency)
- TF-IDF measures how frequently a phrase appears in a document compared to the overall document corpus. Two documents with very similar TF-IDF scores for key phrases may be flagged as duplicates.
- Cosine Similarity
- This technique measures the similarity between two documents by representing them as vectors of phrases and calculating the cosine of the angle between these vectors. A high cosine similarity indicates a likely duplicate.
Example:
In a search for “COVID-19 vaccine research,” multiple documents from different sources may contain very similar information, such as news articles summarizing the same scientific study. Duplicate detection ensures that the user is not overwhelmed by multiple versions of the same content. Instead, they are shown a variety of articles with different perspectives or additional information.
Benefits of Phrase-Based Indexing
- Improved Relevance: Since phrases convey more precise meaning than individual words, this indexing method provides results that are more aligned with the user’s intent. For example, a search query for “best wireless headphones” would return more relevant results because the search engine understands it as a single phrase rather than as separate keywords.
- Contextual Search: Phrase-based indexing allows search engines to recognize related phrases even when exact matches are not present in the document. It considers variations and related phrases, which improves the contextual understanding of the content.
- Semantic Understanding: This approach also enhances the semantic understanding of content. By looking at the relationships between phrases, search engines can differentiate between ambiguous terms and interpret the intended meaning more accurately.
- Reduced Noise in Results: In traditional keyword-based indexing, unrelated documents may rank higher simply because they contain the searched words. Phrase-based indexing filters out irrelevant results by focusing on the actual meaning and context of the phrases.
Applications of Phrase-Based Indexing
- Search Engines: Major search engines like Google use phrase-based indexing to deliver relevant search results by understanding user queries at a deeper level.
- Content Recommendation Systems: Platforms that recommend articles, videos, or products use phrase-based indexing to match user preferences more precisely.
- Natural Language Processing (NLP): NLP tools use phrase-based indexing to understand the context of language in various applications like chatbots, voice assistants, and text analysis.
How to Use Phrase-Based Indexing for SEO Success?
By leveraging phrase-based indexing principles in SEO, you can significantly enhance your site’s visibility and relevance. Focus on optimizing for good phrases, incorporating related terms, using informative anchor text, and clustering content around key topics. This approach aligns with how search engines analyze content contextually, making your SEO efforts more effective.
1. Target High-Value Phrases (Good Phrases)
Phrase-based indexing prioritizes good phrases—phrases that occur frequently and have predictive power. In SEO, this translates to identifying key phrases that are both popular and relevant in your niche.
- Action: Use tools like Google Keyword Planner or SEMrush to find phrases that are commonly searched for in your industry.
- Example: If you’re targeting the tech industry, “artificial intelligence” is a good phrase. It also predicts related terms like “machine learning” and “neural networks.” Incorporating these phrases helps ensure that your content is viewed as highly relevant.
2. Optimize Content for Related Phrases
Phrase-based indexing clusters related phrases together, helping search engines understand the content context more effectively.
- Action: Use semantically related keywords alongside your primary keywords to strengthen your content’s relevancy. For instance, if your target keyword is “best wireless headphones,” use related phrases like “Bluetooth headphones,” “noise cancellation,” and “over-ear headphones.”
- Example: In a blog post about “best wireless headphones,” adding phrases like “long battery life” and “wireless connectivity” improves the chances of ranking higher.
3. Anchor Text Optimization
The patent mentions evaluating anchor text as part of phrase-based indexing. Links with relevant anchor text can enhance both your page’s and the linked page’s rankings.
- Action: Use descriptive and keyword-rich anchor text when linking to other pages. Avoid vague phrases like “click here” or “read more.” Instead, use more context-driven phrases.
- Example: Instead of “click here,” use “learn more about noise-cancelling technology.”
4. Improve Topical Relevance with Clustering
Phrase-based indexing organizes content into clusters of related phrases, helping search engines better understand the main topics of a webpage.
- Action: Structure your content around clusters of related phrases to enhance topical authority. This can be done by covering multiple aspects of a topic within a single page or across related pages.
- Example: If you’re writing about “cloud computing,” you could organize subtopics into sections like “cloud storage,” “cloud security,” and “cloud infrastructure,” ensuring you cover a broader set of related phrases.
5. Document Ranking by Phrase Use
According to the phrase-based indexing system, documents are ranked higher if they contain a large number of related phrases. This principle can be used in SEO to create content that ranks well by focusing on covering more related phrases within your niche.
- Action: Create in-depth content that includes not just your primary keyword but also a wide range of related phrases that could increase the document’s ranking value.
- Example: A well-rounded article on “smart home devices” might also cover related phrases like “smart lighting,” “voice assistants,” and “home automation systems.”
6. Focus on Information Gain
Phrase-based indexing assesses the information gain of phrases, meaning how much one phrase predicts the presence of another. For SEO, focusing on phrases with high information gain can help rank your pages higher for more competitive terms.
- Action: Identify and incorporate phrases that frequently co-occur with your target keywords. These phrases help increase the relevance of your content.
- Example: If you’re optimizing for “best organic skincare products,” including high-information gain phrases like “natural ingredients” and “chemical-free skincare” will strengthen your content.
7. Minimize Duplicate Content
Phrase-based indexing systems are also designed to detect duplicate content by analyzing the phrases used. Duplicate content can negatively impact SEO by confusing search engines about which page to rank.
- Action: Use original and distinct phrases across your web pages. Avoid repeating the same phrases across multiple pages without adding new value.
- Example: Instead of using the same description for multiple product pages, create unique descriptions for each product that highlight different aspects of the product.
8. Leverage Semantic Search
As search engines increasingly use machine learning and NLP (Natural Language Processing) to understand user queries, phrase-based indexing becomes more important.
- Action: Ensure that your content is aligned with user intent by using natural language and answering common questions in your field.
- Example: Create FAQ sections that use phrases typically searched by users, such as “How does cloud computing work?” This ensures your content aligns with common user queries.
Subscribe to Our Newsletter!
My head hurts trying to understand the concept, but you have covered it in simple way. Thank you dude!